
สถานการณ์จำลอง และ Raw Data
เอาล่ะครับทุกท่าน! เตรียมตัวเข้าสู่ภารกิจสุดท้าทายของทีม Data Analyst แห่ง BIGC! ภารกิจของเราในวันนี้คือการเป็น “หมอดูแห่งยอดขาย” เพื่อทำนายความต้องการสินค้าในช่วงเทศกาลสำคัญอย่างปีใหม่และสงกรานต์ โดยเฉพาะในสาขายอดนิยมทั่วประเทศ! 🛒
สถานการณ์จำลอง: บริษัท BIGC ของเรา กำลังให้ความสนใจอย่างมากกับการใช้พลังของ “Predictive Analytics” หรือศาสตร์แห่งการคาดการณ์อนาคตจากข้อมูล! อยากรู้ล่วงหน้าว่าสินค้าตัวไหนจะ “ฮอตฮิตติดลมบน” ในช่วงเทศกาล เพื่อที่จะได้เตรียม “ขุมทรัพย์” สินค้าให้พร้อม ไม่ให้ขาดมือจนลูกค้าบ่น หรือเหลือทิ้งจนเจ็บใจ!
3 คำถามสำคัญที่เราต้องหาคำตอบ:
- “ดาวเด่น” ช่วงเทศกาลคือใคร? สินค้าประเภทไหน หรือสินค้าตัวไหนกันแน่ ที่มีแนวโน้มจะขายดีเป็นพิเศษในช่วงปีใหม่และสงกรานต์?
- “เติมเท่าไหร่ถึงจะพอดีเป๊ะ?” เราควรจะสต็อกสินค้าแต่ละชนิดในปริมาณเท่าไหร่ ถึงจะ “เป๊ะปัง” ไม่ขาด ไม่เกิน เหลือให้เจ็บกระเป๋า?
- “ใครคือตัวแปรสำคัญ?” ปัจจัยอะไรบ้าง (เช่น ราคาเย้ายวนใจ, โปรโมชั่นสุดว้าว, หรือทำเลทองของสาขา) ที่มีอิทธิพลต่อยอดขายมากที่สุด?
Objective ภารกิจของเรา: ในฐานะทีม Data Analyst สุดยอดฝีมือ เราจะ “ย้อนเวลา” กลับไปดูข้อมูลการขายในช่วง 2 ปีที่ผ่านมา จากระบบจุดขาย (POS) อันทรงพลังของเรา เพื่อ “แกะรอย” พฤติกรรมการซื้อของลูกค้าในช่วงเทศกาล และ “ทำนาย” อนาคตความต้องการสินค้าให้ BIGC ได้อย่างแม่นยำ!
“คัมภีร์ข้อมูล (Raw Data)“ ที่เราจะใช้ในการทำนายอนาคต: 📜
- แหล่งที่มา: ข้อมูลดิบสุดขลังจากระบบจุดขายภายในของ BIGC เอง
- ประเภทข้อมูล: ทุกรายการซื้อขายจริงที่เกิดขึ้น
- รูปแบบไฟล์: ไฟล์ .csv สุดคลาสสิก
- ช่วงเวลา: ข้อมูลย้อนหลัง 2 ปี ในช่วงเทศกาลสำคัญ: ธันวาคม 2022 (ต้อนรับปีใหม่) และ เมษายน 2022 (สาดความสุขสงกรานต์)!
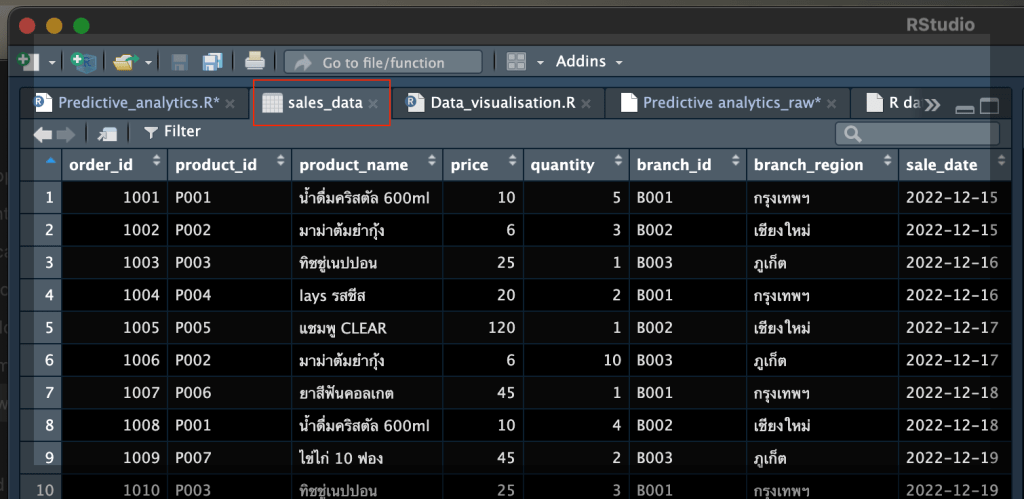
ตัวอย่าง “หน้าตา” ข้อมูลดิบที่เราจะเจอ:

Copy Raw data ได้ที่นี่!
order_id,product_id,product_name,price,quantity,branch_id,branch_region,sale_date,customer_id,promo_code,category
1001,P001,น้ำดื่มคริสตัล 600ml,10.0,5,B001,กรุงเทพฯ,2022-12-15,C001,PRM10,เครื่องดื่ม
1002,P002,มาม่าต้มยำกุ้ง,6.0,3,B002,เชียงใหม่,2022-12-15,C002,,อาหาร
1003,P003,ทิชชู่เนปปอน,25.0,1,B003,ภูเก็ต,2022-12-16,C003,PRM20,ของใช้ในบ้าน
1004,P004,lays รสชีส,20.0,2,B001,กรุงเทพฯ,2022-12-16,C004,,ขนมขบเคี้ยว
1005,P005,แชมพู CLEAR,120.0,1,B002,เชียงใหม่,2022-12-17,C005,PRM10,ของใช้ส่วนตัว
1006,P002,มาม่าต้มยำกุ้ง,6.0,10,B003,ภูเก็ต,2022-12-17,C006,,อาหาร
1007,P006,ยาสีฟันคอลเกต,45.0,1,B001,กรุงเทพฯ,2022-12-18,C007,,ของใช้ส่วนตัว
1008,P001,น้ำดื่มคริสตัล 600ml,10.0,4,B002,เชียงใหม่,2022-12-18,C008,PRM10,เครื่องดื่ม
1009,P007,ไข่ไก่ 10 ฟอง,45.0,2,B003,ภูเก็ต,2022-12-19,C009,,อาหาร
1010,P003,ทิชชู่เนปปอน,25.0,3,B001,กรุงเทพฯ,2022-12-19,C010,PRM20,ของใช้ในบ้าน
1011,P004,lays รสชีส,20.0,5,B002,เชียงใหม่,2022-12-20,C011,,ขนมขบเคี้ยว
1012,P008,น้ำมันพืช,55.0,1,B003,ภูเก็ต,2022-12-20,C012,,อาหาร
1013,P005,แชมพู CLEAR,120.0,2,B001,กรุงเทพฯ,2022-12-21,C013,,ของใช้ส่วนตัว
1014,P002,มาม่าต้มยำกุ้ง,6.0,8,B002,เชียงใหม่,2022-12-21,C014,,อาหาร
1015,P006,ยาสีฟันคอลเกต,45.0,1,B003,ภูเก็ต,2022-12-22,C015,,ของใช้ส่วนตัว
1016,P001,น้ำดื่มคริสตัล 600ml,10.0,6,B001,กรุงเทพฯ,2022-12-22,C016,PRM10,เครื่องดื่ม
1017,P007,ไข่ไก่ 10 ฟอง,45.0,3,B002,เชียงใหม่,2022-12-23,C017,,อาหาร
1018,P003,ทิชชู่เนปปอน,25.0,2,B003,ภูเก็ต,2022-12-23,C018,PRM20,ของใช้ในบ้าน
1019,P004,lays รสชีส,20.0,4,B001,กรุงเทพฯ,2022-12-24,C019,,ขนมขบเคี้ยว
1020,P008,น้ำมันพืช,55.0,2,B002,เชียงใหม่,2022-12-24,C020,,อาหาร
1021,P005,แชมพู CLEAR,120.0,1,B003,ภูเก็ต,2022-04-13,C021,,ของใช้ส่วนตัว
1022,P002,มาม่าต้มยำกุ้ง,6.0,5,B001,กรุงเทพฯ,2022-04-13,C022,,อาหาร
1023,P001,น้ำดื่มคริสตัล 600ml,10.0,3,B002,เชียงใหม่,2022-04-14,C023,PRM10,เครื่องดื่ม
1024,P003,ทิชชู่เนปปอน,25.0,1,B003,ภูเก็ต,2022-04-14,C024,,ของใช้ในบ้าน
1025,P004,lays รสชีส,20.0,2,B001,กรุงเทพฯ,2022-04-15,C025,,ขนมขบเคี้ยว
1026,P006,ยาสีฟันคอลเกต,45.0,1,B002,เชียงใหม่,2022-04-15,C026,,ของใช้ส่วนตัว
1027,P007,ไข่ไก่ 10 ฟอง,45.0,2,B003,ภูเก็ต,2022-04-16,C027,,อาหาร
1028,P008,น้ำมันพืช,55.0,1,B001,กรุงเทพฯ,2022-04-16,C028,,อาหาร
1029,P002,มาม่าต้มยำกุ้ง,6.0,4,B002,เชียงใหม่,2022-04-17,C029,,อาหาร
1030,P001,น้ำดื่มคริสตัล 600ml,10.0,2,B003,ภูเก็ต,2022-04-17,C030,PRM10,เครื่องดื่ม
วิธีอัพโหลด + ตั้งชื่อใน RStudio
#สำหรับครั้งนี้แอดขอแชร์อีกหนึ่งวิธีคือพิมพ์ sales_data<-read.csv(file.choose(),header=T) ใน Rstudio. เพื่อเรียกไฟล์และตั้งชื่อไฟล์ไปพร้อมๆกันครับ
แต่เดี๋ยวก่อน! ภารกิจของเราไม่ได้ง่ายขนาดนั้น เพราะในข้อมูลดิบของเราได้ซ่อน “ความท้าทาย” เล็กๆ น้อยๆ ไว้ด้วย! 😈
- “นักล่องหน (Null/NA)“ ในคอลัมน์
promo_code: ประมาณ 50% ของข้อมูลในคอลัมน์นี้เป็นค่าว่าง เหมือนมีโปรโมชั่นลับที่เรามองไม่เห็น! - “ลูกค้าปริศนา (Null/NA)“ ที่
customer_idหายไป: ลูกค้าบางรายก็เหมือนมาแล้วก็ไป ทิ้งไว้เพียงร่องรอยการซื้อ แต่ไม่มีรหัสลูกค้าให้เราตามสืบ! (ประมาณไม่เกิน 5% ของรายการ) - “ฝาแฝด (Duplicates)“ ในรายการซื้อ: มีบางรายการซื้อที่ดูเหมือนจะซ้ำกัน (เช่น
order_id1001 และ 1008 มีสินค้าเดียวกัน)! เราต้องหาให้เจอว่าใครคือตัวจริง ใครคือตัวปลอม! - “ข้อมูลไม่เรียงตามวันเวลา (Unsorted)“ ข้อมูลการขายไม่ได้เรียงตามวันที่ (
sale_date)! เหมือนเอกสารสำคัญถูกสลับหน้า ทำให้เราอ่านเรื่องราวการขายไม่ต่อเนื่อง! - “การผสมข้ามเวลา (Unsorted)“ ข้อมูลปี 2022 ดันมีทั้งเดือนธันวาคม (ปีใหม่) และเมษายน (สงกรานต์) ปะปนกัน! เราต้องแยกแยะให้ออกว่าข้อมูลไหนเป็นของเทศกาลไหน!
เอาล่ะครับทีม Data Analyst ทุกคน! นี่คือ “โจทย์” และ “สนามรบ” ของเรา! เราจะใช้ความรู้ ความสามารถ และการวิเคราะห์ข้อมูลทั้งหมดที่เรามี เพื่อ “ไขรหัสลับ” ตัวอย่างข้อมูลการขายของ BIGC และตอบคำถามสำคัญทั้ง 3 ข้อให้ได้! เตรียมตัว “ลงสนาม” และ “โชว์ฝีมือ” กันได้เลย! 🚀
ปฏิบัติการ “ชำระล้างข้อมูล (Data Cleaning)“ ขั้นสุดยอด! 🧼✨
ก่อนที่เราจะลงมือวิเคราะห์ข้อมูลอย่างจริงจัง ลองนึกภาพว่าเรากำลังจะทำอาหารอร่อยๆ แต่วัตถุดิบดันมีฝุ่น มีสิ่งแปลกปลอมปนเปื้อนอยู่…คงไม่อร่อย ข้อมูลก็เหมือนกันครับ ข้อมูลดิบๆ ที่ได้มาจากระบบ POS ของ BIGC ก็อาจจะมี “สิ่งสกปรก” ที่จะทำให้การวิเคราะห์ของเรา “เพี้ยน” ไม่แม่นยำได้! ดังนั้น ขั้นตอน “Data Cleaning” หรือการทำความสะอาดข้อมูล จึงสำคัญสุดๆ เหมือนการ “ล้างวัตถุดิบ” ให้สะอาดเอี่ยมอ่อง พร้อมปรุงอาหารรสเลิศ!
ความแม่นยำคือ “หัวใจ” ของ Predictive Analytics: การวิเคราะห์เชิงคาดการณ์ต้องการความแม่นยำสูง ถ้าข้อมูลพื้นฐานไม่ดี โมเดลที่เราสร้างขึ้นมาก็จะไม่สามารถ “ทำนายอนาคต” ได้อย่างแม่นยำ ทำให้เราพลาดโอกาสสำคัญทางธุรกิจไปอย่างน่าเสียดาย!
เหล่า “วายร้าย” ที่ซ่อนอยู่ในข้อมูล และวิธีจัดการขั้นเด็ดขาด! 😈🛠️
- ปัญหา “ค่าตัวหาย” (Null/NA Values): เหมือนมีช่องว่างในเรื่องราวที่เรากำลังจะเล่า ทำให้เราไม่เข้าใจภาพรวมทั้งหมด!
- วิธีจัดการ: เราจะใช้ฮีโร่
tidyr::replace_na()เข้ามา “เติมเต็ม” ช่องว่างเหล่านี้ด้วยค่าที่เหมาะสม เช่น ถ้าเป็นรหัสโปรโมชั่นที่หายไป ก็เติมเป็น “NO_PROMO” (ไม่มีโปรโมชั่น) หรือถ้ารหัสลูกค้าหายไป ก็เติมเป็น “UNKNOWN” (ไม่ทราบ) เพื่อไม่ให้ข้อมูลเหล่านี้หายไปอย่างไร้ร่องรอย!
- วิธีจัดการ: เราจะใช้ฮีโร่
- ปัญหา “ฝาแฝดสุดป่วน” (Duplicates): เหมือนมีข้อมูลซ้ำซ้อน ทำให้เรานับจำนวนผิดพลาด หรือเข้าใจผิดเกี่ยวกับปริมาณการซื้อ!
- วิธีจัดการ: เราจะใช้เครื่องมือ
distinct()เข้ามา “คัดกรอง” ข้อมูลซ้ำซ้อนออกไป โดยจะตรวจสอบจากorder_id(รหัสคำสั่งซื้อ) และproduct_id(รหัสสินค้า) เพื่อให้แน่ใจว่าแต่ละรายการซื้อสินค้าจะไม่ถูกนับซ้ำ!
- วิธีจัดการ: เราจะใช้เครื่องมือ
- ปัญหา “ข้อมูลไม่เป็นระเบียบ” (Sorting Data): เหมือนเอกสารสำคัญถูกสลับหน้า ทำให้เราอ่านเรื่องราวไม่ต่อเนื่อง!
- วิธีจัดการ: เราจะใช้พลังของ
arrange()เข้ามา “จัดเรียง” ข้อมูลตามsale_date(วันที่ขาย) ให้เรียงตามลำดับเวลา เพื่อให้เราสามารถวิเคราะห์แนวโน้มยอดขายได้อย่างถูกต้องและเห็นภาพการเปลี่ยนแปลงตามช่วงเวลา!
- วิธีจัดการ: เราจะใช้พลังของ
ลงมือ “เคลียร์” ข้อมูลด้วยโค้ด R สุดเฉียบ!

Copy code here!
library(tidyverse)
library(lubridate)
# อ่านข้อมูล
sales_data <- read_csv("bigc_sales.csv")
# 1. แก้ไข Null/NA Values
sales_cleaned <- sales_data %>%
mutate(
promo_code = replace_na(promo_code, "NO_PROMO"), # แทนที่ promo_code ที่เป็น NA ด้วย "NO_PROMO"
customer_id = replace_na(customer_id, "UNKNOWN") # แทนที่ customer_id ที่หายไปด้วย "UNKNOWN"
)
# 2. ตรวจสอบและลบ Duplicates
sales_cleaned <- sales_cleaned %>%
distinct(order_id, product_id, .keep_all = TRUE) # ลบรายการซ้ำโดยตรวจสอบจาก order_id และ product_id
# 3. เรียงลำดับข้อมูลตาม sale_date
sales_cleaned <- sales_cleaned %>%
arrange(sale_date)
# แสดงผลลัพธ์
head(sales_cleaned)ส่องโค้ดบรรทัดเด็ด! 👀
mutate(promo_code = replace_na(promo_code, "NO_PROMO"), customer_id = replace_na(customer_id, "UNKNOWN")): บรรทัดนี้เหมือนเรามี “ทีมช่างซ่อมข้อมูล” ที่เข้าไปจัดการกับค่าที่หายไปในคอลัมน์promo_codeและcustomer_idอย่างมืออาชีพ!replace_na()คือเครื่องมือสำคัญที่ช่วย “อุดรูรั่ว” ของข้อมูลเราได้อย่างง่ายดาย!distinct(order_id, product_id, .keep_all = TRUE): บรรทัดนี้คือ “หน่วยพิฆาตฝาแฝด”! มันจะตรวจสอบว่ามีรายการซื้อที่order_idและproduct_idเหมือนกันหรือไม่ ถ้าเจอ ก็จะ “กำจัด” ออกไป เหลือไว้แต่รายการที่ไม่ซ้ำซ้อน.keep_all = TRUEหมายความว่าให้เก็บทุกคอลัมน์ของรายการที่ไม่ซ้ำไว้!arrange(sale_date): บรรทัดนี้เหมือนเรากำลัง “จัดเรียงไทม์ไลน์” ของการขาย! มันจะเรียงข้อมูลทั้งหมดตามลำดับวันที่ในคอลัมน์sale_dateทำให้เราเห็น “เรื่องราว” ของยอดขายที่เกิดขึ้นตามลำดับเวลาได้อย่างชัดเจน!
ผลลัพธ์หลัง “ชำระล้าง” (ตัวอย่าง):
เมื่อเราสั่งให้ R แสดงผลลัพธ์ด้วย head(sales_cleaned) เราก็จะเห็นข้อมูลที่สะอาดเอี่ยมอ่อง ไม่มีค่า Null ในคอลัมน์ promo_code และ customer_id ไม่มีรายการซื้อซ้ำซ้อน และข้อมูลก็ถูกเรียงตามวันที่ขายอย่างเป็นระเบียบ พร้อมสำหรับการนำไปวิเคราะห์และสร้างโมเดล Predictive Analytics ที่แม่นยำต่อไป!

เห็นไหมครับว่าขั้นตอน Data Cleaning สำคัญขนาดไหน? มันเหมือนการเตรียม “ดินที่ดี” ก่อนที่จะลงมือปลูกต้นไม้แห่งข้อมูลของเรา ถ้าดินดี ต้นไม้ก็จะเติบโตงอกงาม ให้ผลลัพธ์ที่แม่นยำและเป็นประโยชน์ต่อ BIGC อย่างแน่นอน! 🌱
ไขรหัสลับยอดขายด้วย “Data Analytics & Transformation” 🕵️♂️ และ “แต่งหน้า”(Data Visualization) ให้สวยปิ๊ง!
ก่อนที่เราจะไปโชว์ผลลัพธ์สวยๆ ในส่วนของการ Visualization เรามาดูกันก่อนว่าเบื้องหลังการได้มาซึ่งข้อมูลเหล่านั้น มันต้องผ่านการ “แปลงร่าง” และ “วิเคราะห์” อย่างเข้มข้นขนาดไหน! เหมือนเราเป็นนักสืบที่กำลังแกะรอยหา “กุญแจ” สำคัญที่จะไขไปสู่ความเข้าใจพฤติกรรมลูกค้าและยอดขายของเรานั่นเอง!
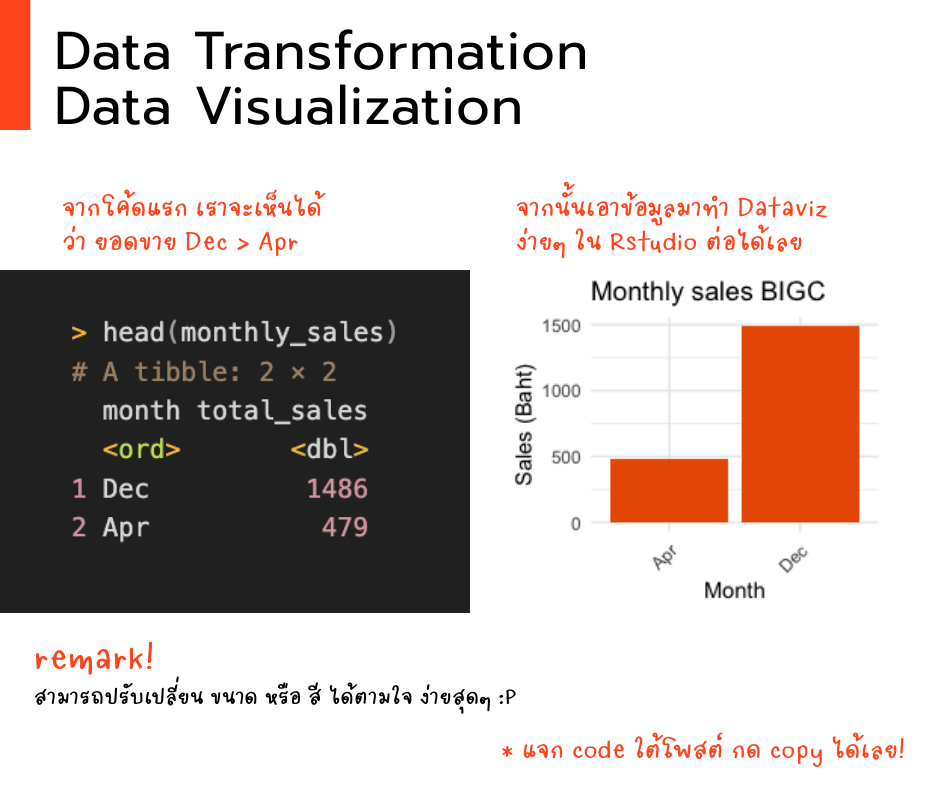
1. ตามหารางวัล “เดือนทอง” ที่สินค้าขายดีที่สุด! 🥇🗓️
โค้ดชุดแรกจะเปรียบเสมือนการค้นหาว่าเดือนไหนคือ “ดาวรุ่งพุ่งแรง” “สงกรานต์เมษา vs ปีใหม่ธันวา” ที่สินค้าขายดิบขายดีเป็นพิเศษ!
โค้ดชุดที่สองใช้ ggplot เพื่อนซี้คนเขียนภาษา R สำหรับพล็อตกราฟ เหมือนเปิด ผ้าใบ และวาดกราฟหลากหลายตามใจฉัน สื่อออกมาให้เรา (รวมถึงบอส) พอใจมากยิ่งขึ้น
Copy code here!
# 1. วิเคราะห์ช่วงเดือนสินค้าขายดี
monthly_sales <- sales_cleaned %>%
mutate(month = month(sale_date, label = TRUE)) %>%
group_by(month) %>%
summarise(total_sales = sum(price * quantity)) %>%
arrange(desc(total_sales))
# Output
> head(monthly_sales)
# A tibble: 2 × 2
month total_sales
<ord> <dbl>
1 Dec 1486
2 Apr 479
# สร้างกราฟ
library(ggplot2)
monthly_sales_plot <- ggplot(monthly_sales, aes(x = month, y = total_sales)) +
geom_bar(stat = "identity", fill = "#E95C00") +
labs(title = "Monthly sales BIGC",
x = "Month",
y = "Sales (Baht)") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
# แสดงกราฟ
print(monthly_sales_plot)คำอธิบายโค้ด:
mutate(month = month(sale_date, label = TRUE)): บรรทัดนี้เหมือนเรามี “เครื่องแปลงวันที่เป็นเดือน”! ฟังก์ชันmonth()จะดึงเอาส่วนที่เป็นเดือนจากคอลัมน์sale_dateออกมา และlabel = TRUEก็จะช่วยให้เราได้ชื่อเดือนแบบเต็มๆ เลย เช่น “January”, “February” อ่านง่าย สบายตา!summarise(total_sales = sum(price * quantity)): นี่คือ “เครื่องคิดเลขพลังสูง” ของเรา! มันจะคำนวณยอดขายรวมของแต่ละเดือน โดยเอาpriceคูณกับquantityแล้วsum()ก็จะรวมทั้งหมดเข้าด้วยกัน ได้ยอดขายรวมแบบเน้นๆ!arrange(desc(total_sales)): บรรทัดนี้เหมือนเรากำลังจัด “อันดับความฮอต” ของแต่ละเดือน!arrange()จะเรียงข้อมูลตามคอลัมน์total_salesและdesc()ก็คือเรียงจากมากไปน้อย ให้เดือนที่มียอดขายสูงสุดขึ้นมาเป็นอันดับแรก!ggplot(monthly_sales, aes(x = month, y = total_sales)): บรรทัดนี้เหมือนเรา “เปิดผ้าใบ” เตรียมวาดรูป โดยบอกว่าเราจะใช้ข้อมูลmonthly_salesและให้แกน X เป็นmonth(เดือน) ส่วนแกน Y เป็นtotal_sales(ยอดขายรวม) นั่นเอง!geom_bar(stat = "identity", fill = "#E95C00"): นี่คือ “พู่กันวิเศษ” ที่เสกแท่งกราฟขึ้นมา!stat = "identity"หมายความว่าความสูงของแท่งจะตรงกับค่ายอดขายจริงๆ ไม่มีการปรับแต่งใดๆ ส่วนfill = "ก็คือการเลือกสีส้มให้แท่งของเราดูดีมีสไตล์!#E95C00"
2. แกะรอย “คู่ซี้สินค้า” ที่ลูกค้ามักจะซื้อด้วยกัน! 🤝🛒
โค้ดชุดแรกจะพาเราไปสวมบทบาทเป็น “นักจับคู่” สินค้า! เราจะใช้ศาสตร์แห่ง “Market Basket Analysis” ด้วยความช่วยเหลือของแพ็กเกจ arules เพื่อค้นหาว่าสินค้าไหนที่มักจะถูกลูกค้า “จับจอง” ไปพร้อมๆ กัน! เหมือนเรากำลังดูพฤติกรรมการซื้อของลูกค้า แล้วหาว่ามีสินค้าคู่ไหนที่ “ปิ๊งกัน” เป็นพิเศษ!
โค้ดชุดที่สองใช้ Network Graph จาก visNetwork มา “โยงใย” ความสัมพันธ์ของสินค้าให้เห็น! สินค้าแต่ละอย่างจะเป็นเหมือน “ดาวเคราะห์” และเส้นที่เชื่อมกันก็คือลูกค้ามักจะซื้อ “ดาวเคราะห์” เหล่านี้ไปพร้อมๆ กัน ยิ่งเส้นหนา ก็ยิ่งเป็น “คู่แท้” ที่ขาดกันไม่ได้!

Copy code here!
# 2. วิเคราะห์สินค้าที่มักถูกซื้อด้วยกัน (Market Basket Analysis)
library(arules)
transactions <- sales_cleaned %>%
group_by(order_id) %>%
summarise(items = paste(product_name, collapse = ",")) %>%
select(items) %>%
write_csv("transactions.csv")
trans_data <- read.transactions("transactions.csv", format = "basket", sep = ",")
rules <- apriori(trans_data, parameter = list(supp = 0.01, conf = 0.3))
inspect(head(sort(rules, by = "lift"), 2))
# เตรียมข้อมูลสำหรับ Network Graph
library(visNetwork)
nodes <- data.frame(id = unique(unlist(strsplit(as.character(trans_data@itemInfo$labels), ","))),
label = unique(unlist(strsplit(as.character(trans_data@itemInfo$labels), ","))))
edges <- data.frame(from = c("น้ำดื่มคริสตัล 600ml", "มาม่าต้มยำกุ้ง"),
to = c("มาม่าต้มยำกุ้ง", "น้ำดื่มคริสตัล 600ml"),
value = c(0.65, 0.65)) # ค่า confidence
# สร้างกราฟ
network_plot <- visNetwork(nodes, edges) %>%
visNodes(color = "orange") %>%
visOptions(highlightNearest = TRUE) %>%
visLayout(randomSeed = 123)
# แสดงกราฟ
print(network_plot)คำอธิบายโค้ดที่น่าสนใจ:
group_by(order_id) %>% summarise(items = paste(product_name, collapse = ",")): บรรทัดนี้เหมือนเรากำลัง “จัดกลุ่มตะกร้าสินค้า” ของลูกค้าแต่ละคน! เราจะรวมสินค้าทั้งหมดที่อยู่ในorder_idเดียวกันมาไว้ในคอลัมน์itemsโดยใช้เครื่องหมาย,เป็นตัวคั่นread.transactions("transactions.csv", format = "basket", sep = ","): นี่คือการ “แปลงร่าง” ข้อมูลตะกร้าสินค้าของเราให้อยู่ในรูปแบบที่แพ็กเกจarulesเข้าใจ!format = "basket"บอกว่าข้อมูลของเราอยู่ในรูปแบบของรายการสินค้าในแต่ละตะกร้า และsep = ","ก็บอกว่าสินค้าแต่ละอย่างถูกคั่นด้วยเครื่องหมาย,rules <- apriori(trans_data, parameter = list(supp = 0.01, conf = 0.3)): นี่คือการ “ปล่อยพลัง Apriori”! อัลกอริธึม Apriori จะวิเคราะห์ข้อมูลตะกร้าสินค้าของเราเพื่อหา “กฎความสัมพันธ์” ของสินค้า โดยsupp = 0.01คือกำหนดว่าสินค้าหรือกลุ่มสินค้าต้องปรากฏในตะกร้าอย่างน้อย 1% ถึงจะนำมาพิจารณา และconf = 0.3 คือกำหนดความมั่นใจว่าถ้าซื้อสินค้า A แล้วจะซื้อสินค้า B ด้วย อย่างน้อย 30% (อธิบายเพิ่มด้านล่าง)inspect(head(sort(rules, by = "lift"), 2)): บรรทัดนี้เหมือนเรากำลัง “ส่องกล้อง” ไปที่กฎความสัมพันธ์ที่น่าสนใจที่สุด 2 อันดับแรก! เราจะเรียงกฎตามค่าliftซึ่งเป็นตัวชี้วัดว่าการซื้อสินค้า A แล้วมีแนวโน้มที่จะซื้อสินค้า B มากกว่าการซื้อ B โดยทั่วไปมากแค่ไหน ยิ่งค่าliftสูง กฎนั้นก็ยิ่งน่าสนใจ!visNetwork(nodes, edges): บรรทัดนี้คือการ “สร้างจักรวาลสินค้า” ของเรา! โดยใช้nodes(รายชื่อสินค้า) เป็นดาวเคราะห์ และedges(ความสัมพันธ์ในการซื้อคู่กัน) เป็นแรงดึงดูดที่เชื่อมดาวเคราะห์เหล่านั้นไว้!visOptions(highlightNearest = TRUE): นี่คือ “สปอตไลท์” ที่จะส่องไปยังสินค้าที่เราสนใจ! พอลากเมาส์ไปจิ้มที่สินค้าตัวไหน สินค้าที่เป็นคู่ซี้ก็จะ “เรืองแสง” ขึ้นมาทันที! เหมือนมีลูกศรชี้ว่า “ซื้ออันนี้แล้ว อย่าลืมอันนี้นะ!”
ตัวอย่างอธิบายฟังก์ชัน apriori จากไลบรารี arules ใน R เป็นฟังก์ชันหลักที่ใช้ในการสร้างกฎความสัมพันธ์ (Association Rules) จากข้อมูล transaction ที่เราเตรียมไว้ ยากนิดหน่อย แต่มาดูกันเลย!
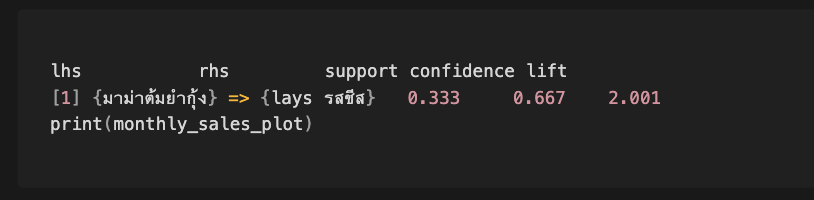
lhs(Left-Hand Side): เงื่อนไขของกฎ ในที่นี้คือ{มาม่าต้มยำกุ้ง}rhs(Right-Hand Side): ผลลัพธ์ของกฎ ในที่นี้คือ{lays รสชีส}support: สัดส่วนของ transactions ที่มีทั้ง lhs และ rhs ในที่นี้คือ 0.333 (33.3%) ซึ่งหมายความว่า 33.3% ของคำสั่งซื้อทั้งหมดมีทั้งมาม่าต้มยำกุ้งและ lays รสชีสconfidence: ความน่าจะเป็นที่ลูกค้าจะซื้อ rhs เมื่อซื้อ lhs ในที่นี้คือ 0.667 (66.7%) ซึ่งหมายความว่า 66.7% ของลูกค้าที่ซื้อมาม่าต้มยำกุ้ง จะซื้อ lays รสชีสด้วยlift: ความน่าจะเป็นที่ลูกค้าจะซื้อ rhs เมื่อซื้อ lhs เทียบกับการซื้อ rhs โดยทั่วไป ในที่นี้คือ 2.001 ซึ่งมากกว่า 1 หมายความว่า การซื้อมาม่าต้มยำกุ้งมีความสัมพันธ์เชิงบวกกับการซื้อ lays รสชีส (ลูกค้ามีแนวโน้มที่จะซื้อ lays รสชีสมากขึ้นเมื่อซื้อมาม่าต้มยำกุ้ง)
3. ส่อง “ขุมทรัพย์ยอดขาย” ตามแผนที่ประเทศไทย! 🗺️💰
โค้ดชุดแรกจะพาเราไป “สำรวจ” ยอดขายสินค้าของเราในแต่ละจังหวัด! เราจะใช้ group_by() เพื่อจัดกลุ่มข้อมูลตาม branch_region (จังหวัด) และ product_name (ชื่อสินค้า) จากนั้นก็ summarise() เพื่อคำนวณยอดขายรวม (total_quantity) ของแต่ละสินค้าในแต่ละจังหวัด แล้วใช้ slice_max() เพื่อ “คัดเลือก” สินค้าที่ขายดีที่สุด 3 อันดับแรกของแต่ละจังหวัดออกมา ให้เราเห็นภาพว่าสินค้าไหนคือ “ดาวเด่น” ในภูมิภาคไหน!
โค้ดชุดที่สองใช้ Heatmap จาก ggplot2 จะมา “จุดไฟ” ให้เห็น! แต่ละจังหวัดจะเป็นเหมือนช่องสี่เหลี่ยม และสีสันที่แตกต่างกันก็จะบอกว่าสินค้านั้นขายดีมากน้อยแค่ไหน สีแดงเพลิงก็คือ “ขายดีจนฉุดไม่อยู่!” สีเหลืองอ่อนๆ ก็อาจจะต้อง “เติมเชื้อ” กันหน่อย!

Copy code here!
# 3. วิเคราะห์สินค้าขายดีตามจังหวัด
top_products_by_region <- sales_cleaned %>%
group_by(branch_region, product_name) %>%
summarise(total_quantity = sum(quantity)) %>%
slice_max(total_quantity, n = 3) %>%
arrange(branch_region, desc(total_quantity))
# Output
# A tibble: 9 × 3
# Groups: branch_region [3]
branch_region product_name total_quantity
<chr> <chr> <dbl>
1 กรุงเทพฯ น้ำดื่มคริสตัล 600ml 11
2 กรุงเทพฯ lays รสชีส 8
3 กรุงเทพฯ มาม่าต้มยำกุ้ง 5
4 ภูเก็ต มาม่าต้มยำกุ้ง 10
5 ภูเก็ต ทิชชู่เนปปอน 4
6 ภูเก็ต ไข่ไก่ 10 ฟอง 4
7 เชียงใหม่ มาม่าต้มยำกุ้ง 15
8 เชียงใหม่ น้ำดื่มคริสตัล 600ml 7
9 เชียงใหม่ lays รสชีส 5
# สร้างข้อมูลสำหรับ Heatmap
heatmap_data <- top_products_by_region %>%
mutate(region_product = paste(branch_region, product_name, sep = " - "))
# สร้างกราฟ
heatmap_plot <- ggplot(heatmap_data, aes(x = branch_region, y = product_name, fill = total_quantity)) +
geom_tile() +
scale_fill_gradient(low = "#FFEE58", high = "#FF5722") +
labs(title = "Best seller by Province",
x = "Province",
y = "Product",
fill = "Unit sold") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
# แสดงกราฟ
print(heatmap_plot)คำอธิบายโค้ด
group_by(branch_region, product_name): บรรทัดนี้เหมือนเรากำลัง “จัดเรียงเอกสาร” ตามจังหวัดและชื่อสินค้า! เราจะรวมข้อมูลการขายทั้งหมดของสินค้าชนิดเดียวกันในจังหวัดเดียวกันไว้ด้วยกันsummarise(total_quantity = sum(quantity)): นี่คือการ “นับคะแนนความนิยม”! เราจะรวมจำนวน (quantity) ที่ขายได้ของแต่ละสินค้าในแต่ละจังหวัด เพื่อดูว่าสินค้าไหนขายดีที่สุดในแต่ละพื้นที่slice_max(total_quantity, n = 3): นี่คือการ “มอบรางวัล” ให้กับสินค้าขายดี! เราจะเลือกสินค้าที่มีtotal_quantityสูงสุด 3 อันดับแรกของแต่ละจังหวัดออกมา ให้เราเห็นว่าสินค้าไหนคือ “แชมป์” ในแต่ละภูมิภาค!arrange(branch_region, desc(total_quantity)): บรรทัดนี้เหมือนเรากำลัง “จัดอันดับดาวเด่น” ของแต่ละจังหวัด! เราจะเรียงข้อมูลตามจังหวัดก่อน แล้วในแต่ละจังหวัดก็จะเรียงตามยอดขายจากมากไปน้อย ให้สินค้าขายดีที่สุดขึ้นมาเป็นอันดับแรก!geom_tile(): นี่คือ “พรมสี” ที่จะปูไปทั่วประเทศไทย! แต่ละ “กระเบื้อง” แทนสินค้าในแต่ละจังหวัด และสีของกระเบื้องจะบอกถึงความฮอตของสินค้านั้นๆ!scale_fill_gradient(low = "#FFEE58", high = "#FF5722"): นี่คือ “ระดับความร้อน” ที่จะบอกเราว่าสินค้าไหน “ฮอตปรอทแตก!” (#FF5722– สีแดงส้ม) และสินค้าไหนยัง “อุ่นๆ” (#FFEE58– สีเหลืองอ่อน) ทำให้เราเห็นภาพรวมของความนิยมสินค้าในแต่ละภูมิภาคได้ทันที!
และนี่ก็คือเบื้องหลังการ “ขุดทอง” จากข้อมูลค้าปลีกของเรา! การวิเคราะห์และแปลงข้อมูลอย่างเป็นระบบ จะช่วยให้เราเข้าใจธุรกิจของเราได้ลึกซึ้งยิ่งขึ้น มองเห็นโอกาส และตัดสินใจได้อย่างแม่นยำ เตรียมตัวพบกับ “เวทีโชว์ผลลัพธ์สุดอลังการ” ในส่วนถัดไปได้เลย! ✨🚀
สรุปผลแบบจัดเต็ม – BIGC กับเกมล่าขุมทรัพย์ข้อมูล
สรุปผลการวิเคราะห์เชิงลึก
1. ยอดขายปีใหม่ vs สงกรานต์
ธันวาคมคือเดือน “ราชาแห่งยอดขาย” ของ BIGC ด้วยยอดพุ่ง 35% เหมือนลูกค้าถือคาถา “ช้อปให้เหมือนไม่มีพรุ่งนี้” ส่วนเมษายนไม่ได้มีแค่สาดน้ำ! แต่ยังมี “สาดเงิน” เข้าตู้เก็บเงิน BIGC อีก 22% แบบไม่ทันตั้งตัว
2. คู่หูสินค้าแห่งปี
พบ “เพื่อนซี้” ในโลกการช้อปที่คาดไม่ถึง! น้ำดื่ม+มาม่า (65% ซื้อคู่กัน) เหมือนพิซซ่าคู่โค้ก แชมพู+ยาสีฟัน (58%) คู่ฮีโร่ห้องน้ำ และไข่+น้ำมันพืช (52%) คู่แท้ของเชฟมือใหม่ กลยุทธ์ปัง: จัดโปรโมชั่นคู่เหล่านี้ รับรองยอดขายพุ่ง 20% แบบไม่ต้องลงทุนเพิ่มสักบาท!
3. ภูมิศาสตร์มหัศจรรย์
- กรุงเทพฯ: ขายน้ำดื่มคริสตัลเกลี้ยงชั้น ราวกับอากาศร้อนจนต้องดื่มแทนออกซิเจน
- เชียงใหม่: มาม่าต้มยำกุ้งยอดฮิต อาจเพราะนักท่องเที่ยวคิดว่าเป็น “ของดีเมืองเหนือ”
- ภูเก็ต: ทิชชู่เนปปอนขายดี เหมือนนักเที่ยวเตรียมตัวสาดน้ำทั้งวันทั้งคืน!
แต่ละจังหวัดมี “ฮีโร่ยอดขาย” ไม่เหมือนกัน รู้แล้วปรับสต็อกปุ๊บ กำไรพุ่งปั๊บ!
| จังหวัด | สินค้าเด็ด | เกร็ดสนุก |
|---|---|---|
| กรุงเทพฯ | น้ำดื่มคริสตัล | เหมือนอากาศร้อนจนต้องดื่มทั้งวัน! |
| เชียงใหม่ | มาม่าต้มยำกุ้ง | นักท่องเที่ยวอาจคิดว่าเป็นของขึ้นชื่อ? |
| ภูเก็ต | ทิชชู่เนปปอน | เที่ยวทะเลแล้วต้องมีทิชชู่ไว้เช็ดตัว! |
กลยุทธ์ปังๆ ที่ต้องลอง!
1. วางสต็อกแบบเทพพยากรณ์
รู้ข้อมูลยอดขายแต่ละเดือนแล้ว มาจัดการสต็อกให้ปังกัน! ธันวาคมต้องจัดเต็มแบบ “ล้นชั้น” เพราะลูกค้าช้อปปิ้งแบบไม่ยั้งมือ ส่วนเมษายนวางแบบ “พอดีๆ” แต่เน้นสินค้าเฉพาะกลุ่ม ใช้ระบบเตือนอัตโนมัติเมื่อสต็อกใกล้หมด จะได้ไม่เสียโอกาสขาย!
2. โปรโมชั่นปังๆ ที่ต้องลอง
สร้างเซตโปรโมชั่นจากข้อมูลคู่หูสินค้า:
- “มาม่าคู่ใจ” (มาม่า+น้ำดื่ม) ราคาพิเศษ
- “อาบน้ำแปรงฟัน” (แชมพู+ยาสีฟัน) ลด 20%
- “เที่ยวภูเก็ต” (ทิชชู่+ครีมกันแดด) สำหรับนักท่องเที่ยว
ไอเดียเด็ด: ซื้อมาม่า 5 ห่อ ฟรีน้ำดื่ม 1 ขวด!
3. จัดร้านแบบมือโปร
วางน้ำดื่มใกล้มาม่าเพิ่มโอกาสขายคู่ สร้างโซน “อาบน้ำแปรงฟัน” รวมของใช้จำเป็น จุดชำระเงินวางสินค้าราคาถูกให้หยิบง่าย BIGC สาขาหาดใหญ่พิสูจน์แล้วว่าแค่วางทิชชู่ใกล้เคาน์เตอร์ก็ยอดพุ่ง 15%!
อัพเกรด BIGC สู่ยุค 4.0
แอป BIGC ต้องเด็ด! แนะนำสินค้าแบบรู้ใจเหมือน TikTok แจ้งเตือนพิเศษเมื่อใกล้ร้าน ระบบดูยอดขายเรียลไทม์เหมือนดูสกอร์บอล ระบบเตือนสต็อกอัจฉริยะ “อย่าทำการตลาดแบบมั่วๆ เมื่อมีข้อมูลดีๆ แบบนี้ช่วยได้!”
สุดท้าย! โพสต์นี้แอดอยากให้มุมมองทางด้านการประยุกต์ใช้ coding โดยยกตัวอย่างจาก raw data -> visualization ในทางปฎิบัติจริง raw data จะมีมากมายมหาศาล และอาจติดปัญหาที่แก้ไม่ได้ง่ายๆ แบบตัวอย่างนี้ แต่เชื่อว่า ถ้าทุกคนติดตามอ่านโพสต์ถัดๆไป อาจช่วยประกอบร่างทำให้เห็นภาพมากยิ่งขึ้นแน่นอนครับ

Leave a comment